Projects
In-Progress
Integrated RL Simulation & Telemetry Platform
Unified RL pipeline for 2D/3D tasks with live telemetry and reproducible runs.
More details
Problem
I want something I can carry into future projects, and a centralised telemetry platform will consolidate project logs and streamline progress.
Approach
Start deliberately small: build a simple 2-D reinforcement-learning maze solver and use it to stand up the display. Keep everything observable: emit metrics, logs, and video frames; save the settings, random seed, code version, and checkpoints; and grow the system as I learn more about reinforcement learning and web development.
PhD Planning: Robot Learning for Human Robot Collaboration
Long-term interest: safe, co-adaptive RL for human-in-the-loop technology.
More details
Problem
Robots can execute narrow tasks quickly, but they lack the directive a human provides. For robots and people to work together in the physical world, we need practical, two-way communication and safe co-adaptation. Reinforcement-learning for human-robot interaction (HRI) is promising, but the required data are costly to collect and often bespoke, which makes results hard to compare and reuse.
Approach
Map what works today and build on it. Start with small, reproducible studies that combine: (1) uncertainty-aware perception and intent inference, (2) co-adaptive control with safety constraints, and (3) preference-informed learning to keep humans in the loop. Control data costs by prototyping in simulation first (Unity/Gazebo), using scripted user models and teleoperation for early signals, then moving to focused human studies.
Arch Linux Migration & Dev Environment Automation
NVIDIA 3060 laptop on Arch: reproducible, CUDA-ready, one-command bootstrap.
More details
Problem
Windows made GPU training and reproducibility fragile and slow. I want a lean Linux workstation I can rebuild from scratch at any time, same tools, same drivers, so progress isn’t blocked by the machine. I’ll start on my second-hand 3060 laptop I'd acquired for RL in South Korea, so breakage is safe.
Approach
Use Arch Linux with everything written and designed as code. Automate the full stack: bootloader, disk layout and filesystem, NVIDIA drivers, packages, dotfiles, containers, and the Python toolchain; mirror the process in Ansible for unattended reinstalls on new hardware or a clean disk.
The Design and Evaluation of Haptic Feedback Methods and Environmental Impacts on a Wearable Navigation System

A comparitive study on two haptic feedback methods for a wearable navigation aid used by the visually impaired.
Built a wearable navigation system (RGB-D VSLAM, APF navigation, haptic actuation) with EEG event logging. Trials showed fixed reference haptic cues outperformed rotational haptic ques on success, safety, and reaction time.
Highlights
- End-to-end lightweight wearable system with RGB-D perception, VSLAM, haptic navigation
- Controlled comparison of compass vs rotational-based feedback
- EEG event logging aligned to haptic navigation cues for later analysis
- Reproducible ROS/Arduino testbed for assistive robotics
Case study
Problem
Indoors, GPS is unreliable. According to cognitive science, we understand haptic feedback best when a fixed reference point is utilised. However, our mobbility is naturally coordinated through left and right channels. Will fixed reference point haptic cues, paired with RGB-D SLAM, guide users more clearly than pull-based rotational ques? What are the other critical factors in wearable navigation systems?
Approach
ROS pipeline with RealSense RGB-D perception, RTAB-Map localisation, APF navigation, and Arduino-driven actuators. Two feedback modalities were implemented: (i) compass pressure with a back reference, and (ii) tightening straps around either shoulder. All cues and motor commands were timestamped and logged, together with EEG event markers, for later cognitive workload analysis.
Experiments
Four blindfolded participants navigated fixed routes in textured and plain rooms with both systems and 3 distinct obstacles. Metrics included success, collisions, odometry loss, reaction time, and qualitative feedback. SLAM stability was analysed under texture and turning-rate changes.
Results
Compass cues achieved higher success (83–77% vs 50–66%), fewer collisions (0–0.42 vs ≤1.17), and faster reactions (3.4–3.7 s vs ~4.5–4.9 s). Textured environments stabilised VSLAM, while rapid turns remained a failure mode. Participants reported compass cues clearer and more distinguishable; pulling was rated more natural and comfortable.
Key challenges
- Limited servo torque constrained haptic salience
- VSLAM degraded during rapid turns and in plain environments
- Small sample size limited statistical power
- Multi-device ROS over Wi-Fi/TF frames introduced timing complexity
What I learned
- Body-referenced compass cues are clearer than pull-based cues indoors
- Visual texture drives VSLAM latency more than move speed
- Event-synchronised EEG logging is practical and informative for later analysis
Next steps
- Lighter, higher-torque actuators with adaptive feedback
- Multi-camera or fusion for robust SLAM; larger participant study
Image gallery (4)


Reinforcement Learning-Based Control of a Quadruped Agent in a Simulated Sumo Arena
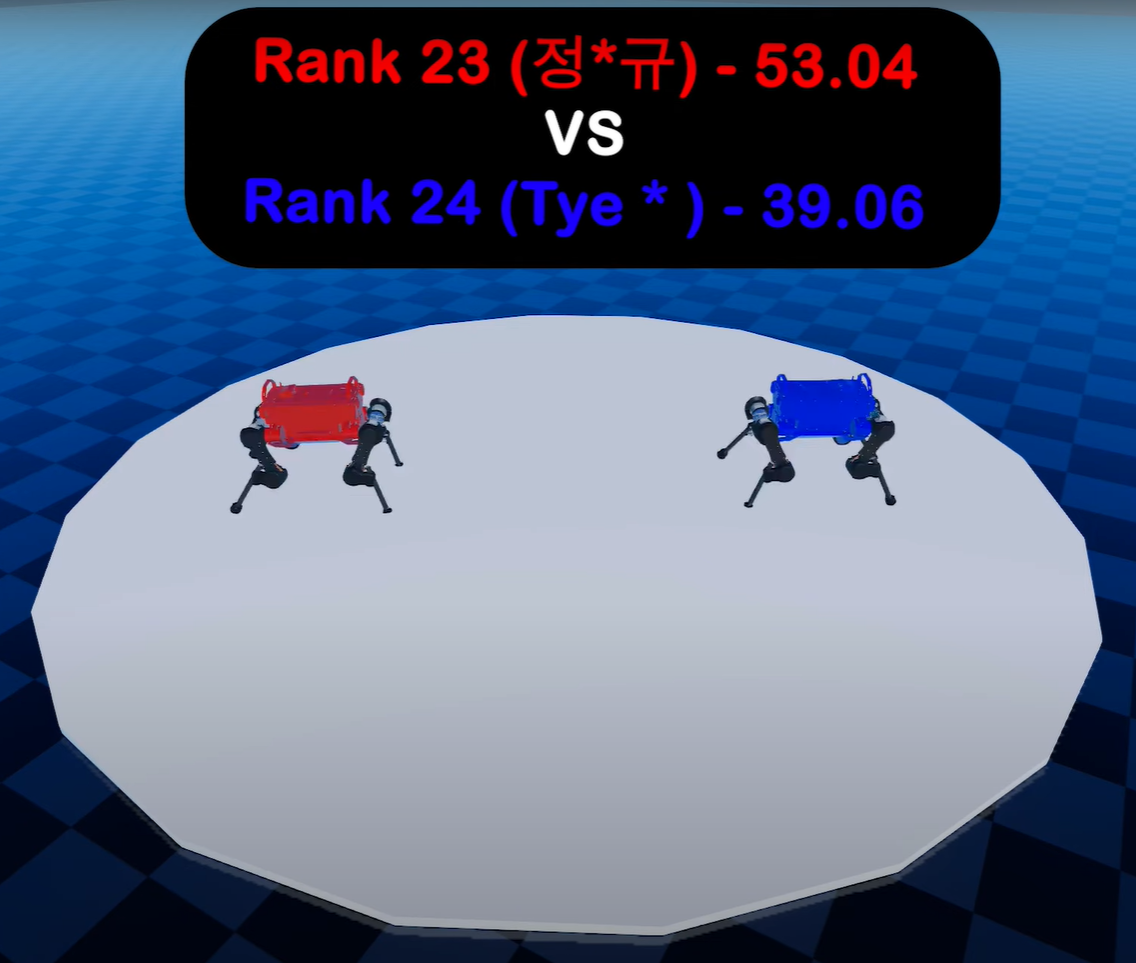
Proximal Policy Optimisation (PPO) with a simple, reward-embedded curriculum in RaisimGym; an emergent “leap” opening appeared.
Trained full ANYmal with joint-torque control and a two-stage curriculum; analysed learning curves, hyperparameters, and emergent tactics under adversarial contact.
Highlights
- Implemented PPO baseline in PyTorch with vectorised simulation and a two-stage curriculum
- Shaped rewards for stability, useful approach, impact, and centre control; tuned γ=0.998 and λ=0.95
- Observed emergent “leap” opener plus edge-pushing; diagnosed failure cases and reward side-effects
Case study
Problem
Quadruped control under adversarial contact is high-variance and sparse-reward. The agent must balance stability and aggression in continuous action space while avoiding brittle policy updates.
Approach
Train with Proximal Policy Optimisation in PyTorch on a vectorised RaiSim/RaisimGym environment (100 parallel arenas). Use a simple curriculum embedded in the reward: far from centre → emphasise approach/impact and forward velocity; near centre → emphasise stability/centre control. Include reward terms for torque cost, centre-of-mass height, and body pitch. Tune PPO with γ=0.998, λ=0.95.
Experiments
[“Baseline PPO vs. curriculum-augmented PPO; measure win rate, reward progression, and stability proxies”, “Ablate reward terms (impact, useful-distance, stabilisers) to expose side-effects”, “Qualitative analysis of emergent tactics (opening leaps, edge pushing) and failure modes”]
Results
The curriculum accelerated early learning and improved robustness relative to the baseline. Policies discovered a high-impact “leap” opener and edge-pushing behaviour. In evaluation, placement was 24/32 with ~25% win rate; failures were often self-destabilisations after the leap.
What I learned
- “Contact = good” accidentally encourages sticking to the opponent; reward should favour destabilisation, not mere impact
- Curriculum design matters; centre-aware staging improved sample efficiency and stability
- Limited opponent diversity in training capped generalisation; richer opponents are needed
Next steps
- Introduce self-play and opponent ensembles; apply domain randomisation for contact, friction, and mass
- Rework reward to penalise sustained contact and explicitly reward opponent destabilisation/outs
- Add safety terms (anti-flip) and richer observations; explore longer horizons and early-stopping criteria
Image gallery (3)

A Feasibility-Aware Portfolio for the Design & Installation of a Hybrid Tidal & Wind Farm in the Severn Estuary

Feasibility study comparing tidal, wind, and hybrid options in the Severn Estuary; hybrid was assessed but wind-only was recommended as most feasible and lowest cost.
Mapped bathymetry and resources, designed wind layouts (21 × 15 MW) with wake-aware spacing, routed inter-array cabling, and scoped grid/substation options. Tidal potential was analysed but co-location proved impractical; the wind-only design achieved the lowest LCOE under the stated assumptions.
Highlights
- Built bathymetry and wind/tidal resource layers and mapped feasible corridors
- Wind layout: west-oriented rows, ~7D × 4D spacing; Jensen/Park with Gaussian follow-up checks
- Cable routing via MST + differential evolution; grid as MVAC with a single onshore substation
- Condition-monitoring costs and OPEX assumptions included to inform downtime and LCOE
Case study
Problem
The Severn Estuary has strong tidal flows but complex bathymetry and strict siting constraints. The question: can a hybrid tidal–wind portfolio deliver reliable power for local industry at a competitive cost once channels, shipping lanes, wildlife zones, and seabed conditions are respected?
Approach
Integrate bathymetry and resource data to map feasible corridors; design wind layouts and preliminarily size foundations; model wakes and array spacing; optimise inter-array cable routing; and design grid and substation options. Assess economics via levelised cost of energy with sensitivity to downtime and intermittency.
Experiments
[“Compare tidal-only, wind-only, and hybrid layouts at candidate sites”, “Sweep spacing/orientation and cable topologies to trade off yield, losses, and maintainability”, “Test sensitivity to device availability, maintenance windows, and grid-connection distance/tariffs”]
Results
Wind-only layouts achieved the lowest levelised cost of energy under the study assumptions. Economies of scale in turbine ratings, installation vessels, O&M logistics, and a mature supply chain dominated. Hybrid layouts offered smoother supply but were impractical here due to depth, seabed, and electrical-integration mismatches, and came with higher LCOE. Siting constraints around channels and shipping lanes remained key drivers.
What I learned
- Wind-only is most cost-effective at this site; hybridisation improves reliability but adds cost/complexity
- Early condition-monitoring integration reduces projected O&M costs
- Cable routing and substation siting materially affect both losses and installation costs
Next steps
- Higher-resolution CFD for wakes and local bathymetry effects
- Longer multi-year environmental series to stress-test variability and downtime
- Policy-aware economics (e.g., Contracts for Difference scenarios) and refined CAPEX/OPEX ranges
- Early engagement with navigation and wildlife stakeholders to validate corridors and exclusions
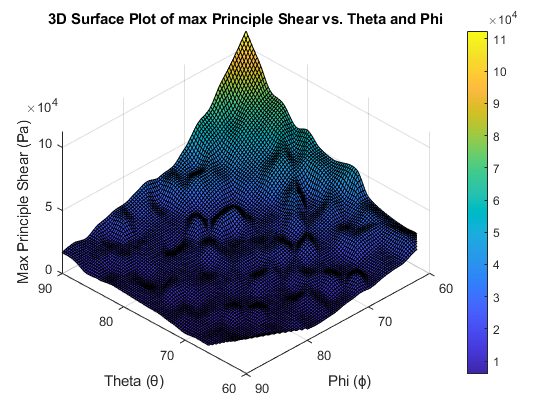
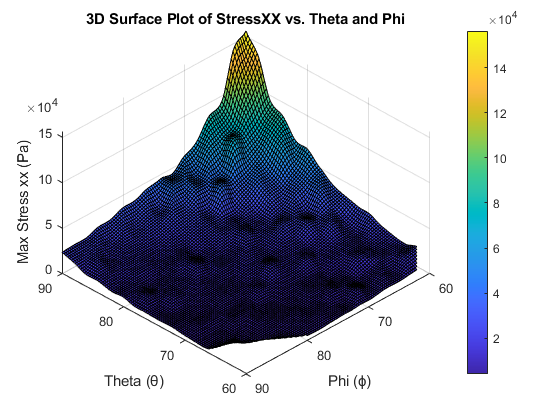
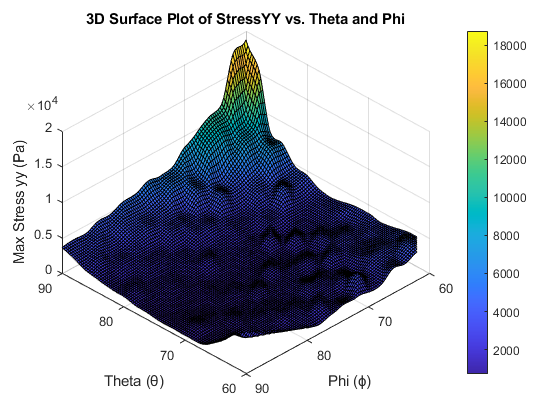
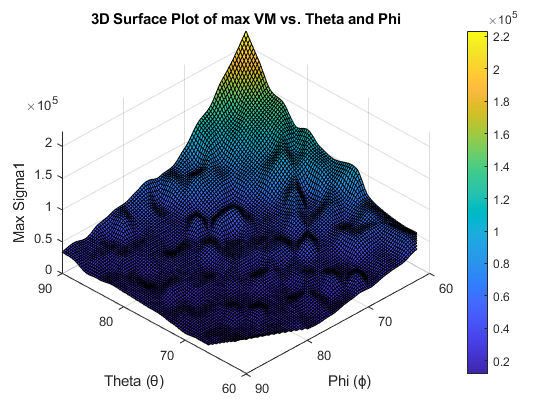
Finite Element Modelling and Optimisation of a 2D Composite Wing Section

Custom Python FEM with differential evolution cut Von Mises stress by ~25% at <1% area error.
Implemented 8-node quadratic elements with Gauss quadrature; θ–ϕ parametric sweeps and optimisation identified a robust sweet spot while enforcing area and orthotropic behaviour.
Highlights
- Implemented solver with 8-node quadratic elements
- Efficient sparse stiffness matrix handling
- Automated θ–ϕ sweeps and convergence checks
Case study
Problem
Reduce peak stress in a composite wing section while strictly maintaining area and orthotropic response.
Approach
Python FEM with Gauss quadrature; constraint enforcement via trigonometric forms and iterative solvers; differential evolution across θ–ϕ parameters.
Experiments
Sweeps over θ, ϕ (60–90°) across material sets (E₁, E₂, G₁₂). Visualised stress fields and convergence.
Results
~25% reduction vs baselines; best region θ=60–64°, ϕ=83–87°; <1% area deviation; stress redistribution confirmed across the section.
What I learned
- Stability hinges on constraint enforcement and eliminating non-finite solutions
- Small angular changes in θ have outsized effects on stress concentrations
Next steps
- Extend to 3D with dynamic loads and multi-objective optimisation (stress, weight, stiffness)
Image gallery (9)